Migrating data across services

I’m a Staff Engineer with over a decade of experience in building and scaling software solutions, specializing in Ruby on Rails and AWS. I've worked with startups and scaleups to turn ideas into robust, scalable products. I'm passionate about writing clean, maintainable code while balancing rapid iteration with long-term stability.
Beyond coding, I write about a few interesting topics on my blog. If you like to read about clean code, refactoring, team culture and productivity, do check my blog.
With reference to my last post and comment on the corresponding LinkedIn post, I’m explaining how we planned to migrate data while transitioning to microservices architecture. There can be multiple approaches to do the same. In a nutshell - we simply want to replicate the data to the new service in a reliable manner at scale.
Dump and restore the table on the database level - Whatever database you’re using, there should be some utility that allows you to do the same. But this is a one-time operation, and doesn’t ensure continuous sync of data. For the systems that hardly change, we can do this. Another thing that we assume here is that schema is the same. Often, when we transition to services, some columns change or get removed (eg. foreign keys that no longer exist in the new system). So this is very less likely to be used.
Setup hooks in old service & continuously sync data - I assume that your MVC architecture would help you to set up such hooks. Eg. we use
after_commitcallbacks in Rails models to replicate such data. And some custom scripts (or rails console) to backfill existing data. Depending on the size of the data this might take a lot of time to backfill existing data, but should replicate the complete data on the new system.
We used the second approach, architected by Nimish Mehta (Senior Staff Engineer @ LocoNav). Even to implement this approach, there are multiple ways, where each has its own complexity and reliability:
Directly replicate data - Here, we’ll simply use the hook in the first application to hit some REST/grPC endpoint of the second application. This should work well till the second system is up and running. In case the second system goes down, our application should have a sufficient retry mechanism before it stops sending further data or marking the current packet as
failed. More things can happen. Considering a large system, where many such use cases will exist, it was inefficient to build this intelligence in all of them. We needed a better solution.
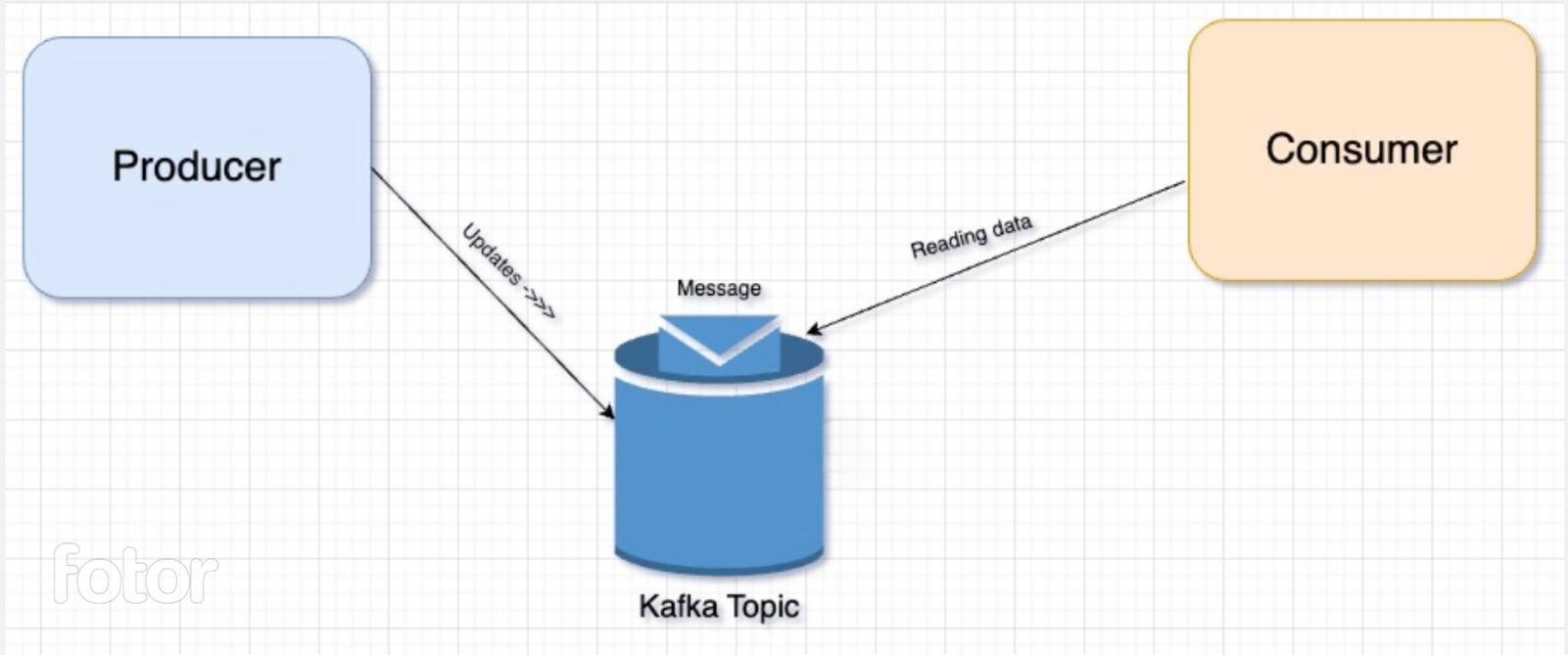
Producer-consumer pattern - We thought of setting up a queueing mechanism using Kafka topics. The primary app (producer) shall publish the data on Kafka topic and the new app (consumer) shall read the data from the Kafka topic whenever it is available. Though this sounded good, it would mean that all such consumer applications shall have the logic to read Kafka topics and maintain success/failure logs. This was again adding complexity to each consumer application, and hence this solution was not optimized for the long run.
Setup an app in the middle - The best solution that we found was to have an app between producer and consumer. So it goes like this - your producer app publishes the data on the Kafka topic and your consumer app exposes a REST endpoint that accepts data in a known format. In the middle, we have an application that takes care of:
Reading data from Kafka.
Formatting it to JSON (from an optimization perspective, we published in protobuf format).
Pushing to consumer application’s REST endpoint.
Having enough retries and a lot of configuration around the same.
Scalable, partitioned database that stored logs of all requests sent to the REST endpoint.
Provision to retry up to
MAX_RETRIES(configurable) per use case.Provision to retain success/failure logs up to certain hours/days (configurable), and much more.
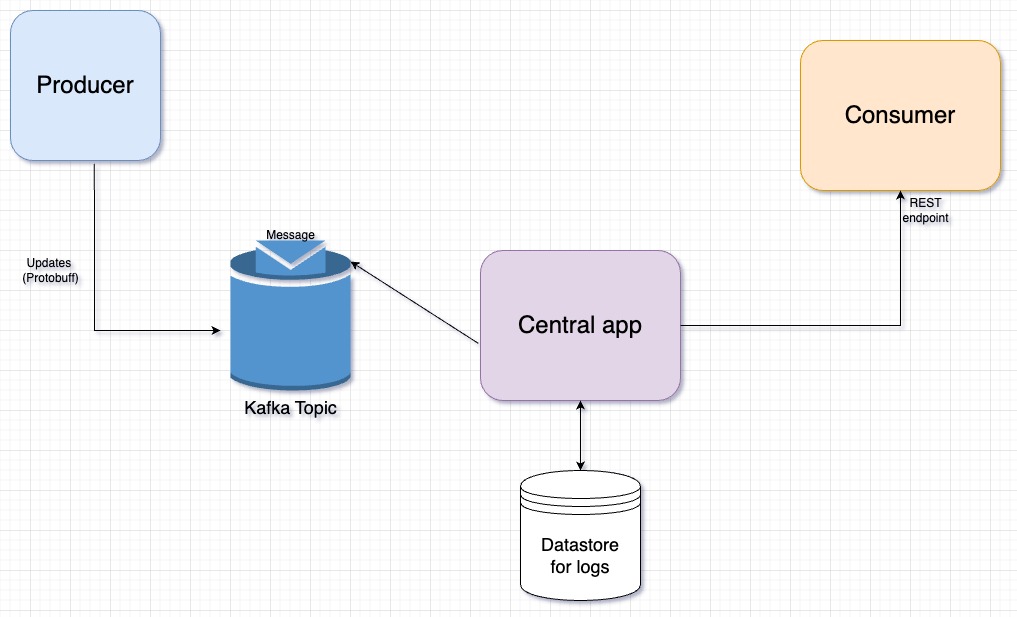
We found the third architecture best for our use case because it has almost zero duplication of code/optimizations on producer or consumer end. Also, in case we need to build anything in future (eg. a UI to query failure logs, or a button to retry), we’d just need to build in the central app. From our experience, I can say that it has solved a lot of pain for other teams because success/failure logs become large with time and none of the team need to worry about it because the team maintaining this central app (“developer productivity team”) takes care of that. This simplifies both apps and life of other developers 😇.
See you guys in the next post.




